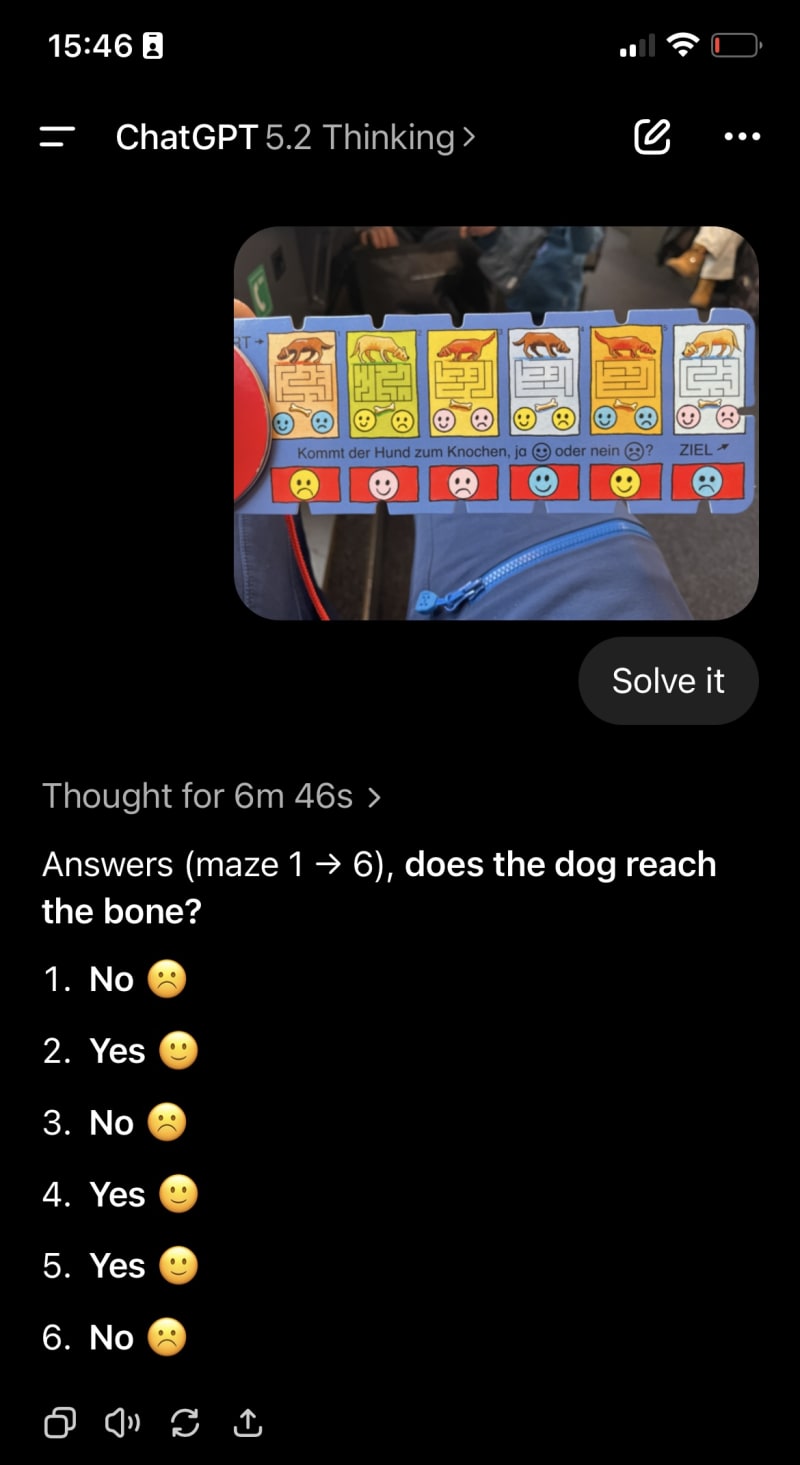
Last weekend, my son was working on a Bandolino puzzle where he had to match questions to answers with a piece of string.
OpenAI just released GPT–5.2 last week, claiming it "performs at or above human expert level" across vision, math, and physics benchmarks [1]. I was curious how long it would take GPT–5.2 to solve it—it failed completely.
How can such a powerful model fail at a task that a four-year-old solved in under a minute after seeing it for the first time?
Andrej Karpathy coined the term "jagged intelligence" for this phenomenon [2]. LLMs can solve complex problems that seem hard to humans while failing at tasks that seem trivially easy. Unlike human intelligence, where abilities tend to correlate and develop together, LLM capabilities are jagged and unpredictable.
To put it another way: while these models are extremely powerful, they can't be trusted.
What does this imply for deploying LLMs in production settings?
(1) Benchmarks give you no guarantees—you have to evaluate models on your own tasks.
(2) Your overall system has to be tolerant of these jagged edges. Use LLMs for the tasks that they are good at and keep a human in the loop on all critical decisions.
(3) You have to take security extremely seriously. Meta's "Agents Rule of Two" is a great framework for AI agent security that is simple to remember and apply in practice [3].
At Ren Systems, we leverage LLMs extensively to create value for our users. But it's always our users who ultimately take action.
What's one lesson you've learned deploying LLMs in production?
(References/links in first comment below)
References/links
[1] Introducing GPT-5.2 – https://openai.com/index/introducing-gpt-5-2/
[2] Andrej Karpathy on jagged intelligence – https://x.com/karpathy/status/1816531576228053133
[3] Meta's Agents Rule of Two – https://ai.meta.com/blog/practical-ai-agent-security/