I know that the following is very unscientific and just "vibes," but in my personal experience, Anthropic's models have severely degraded since shortly before Opus 4.7 was released about six weeks ago. And my initial impression from the week or so I've spent with 4.8 is that it isn't any better.
Three months ago, Opus 4.6 was great and highly reliable. However, the performance of the recent 4.7 and 4.8 models is much less reliable for me. They often think for a long time before suddenly speeding up and answering suspiciously quickly. I now also frequently see the model correct itself in the final answer, as if it hadn't already settled on its answer during the reasoning tokens. And the models seem to lose context even in short conversations of no more than a few thousand tokens. For a while, I switched to the Opus 4.6 1M context window model instead of 4.7, but I feel that 4.6 has also degraded in recent weeks, as surprising as that may sound.
I'm reminded of the time around March/April, when Anthropic admitted that a few changes to the Claude Code harness had degraded its performance. According to their postmortem, the bugs were in the harness, not the model weights or the API. But this time, I don't think it's only the Claude Code harness, because I'm seeing the same problems in the Claude desktop app. Yesterday I asked Opus 4.8 to write some SQL queries for an investigation, a task I've done almost daily for well over a year. I usually provide the table schemas and indices, and the models normally write long, complex queries based on my instructions without trouble. This time, it just wouldn't understand what I needed, and I had to be far more explicit than ever before, even though it was a relatively simple task.
I wonder whether it's quantization or context compaction because of Anthropic's compute crunch, or whether the models have been overtrained on benchmarks with very clear task descriptions. But I need models to read between the lines and remember the context of a conversation. Otherwise, I might as well write the SQL query, code, or text myself if I have to be very explicit. I haven't tried any serious workloads on local models yet, and I'm sure I'd be even more frustrated than with the latest Opus models.
The crazy thing is that I don't want the models to be bad. I'd much rather write about the cool things I'm building with them than about how they've regressed. I genuinely want Anthropic models to be good, and the most frustrating part is knowing they were great just a few months ago, but having no way to access them now.
If you're still using BERT-style token classification models for NER tagging in production, you should probably reevaluate.
Last summer, we replaced our token classification model with Google's Gemini 2.5 Flash Lite for NER tagging people, companies, and locations on millions of news articles per day. At first, it felt wrong and overkill to replace a well-established, standard approach with a generative model. However, on our own evaluation datasets, the LLM outperformed every BERT model we had implemented previously because it brings so much more contextual understanding to the task.
There are a few obvious advantages to using LLMs for NER tagging. For example, LLMs can easily handle text like "Michael and Jennifer Smith" and correctly extract both "Michael Smith" and "Jennifer Smith" as separate people. They are also much better at handling formatting issues and messy edge cases you inevitably encounter in real-world data at scale.
Deployment is also dramatically simpler: instead of managing model serving infrastructure, you're calling an inference API that you can parallelize and scale easily. Additionally, you automatically benefit from LLMs getting better and cheaper over time without changing anything on your end, provided that you have a solid eval dataset.
We're now processing close to 1B input tokens and producing 100M output tokens per day on this pipeline alone. The most popular pre-trained NER models on Hugging Face are still downloaded millions of times per month, which tells me that structured text extraction with LLMs is one of the most underrated applications right now.
Here is something interesting I've learned in the past few weeks about building AI products: AI is not great at writing prompts for itself. It's a trap I've fallen into repeatedly, and I suspect many others have too.
It usually goes like this: You start building a feature that uses one or more prompts for an LLM call, agent, or workflow with a coding agent like Claude Code. The first version works, and the output is ok, but not great. So you show your coding agent some examples and tell it what you don't like, and it edits the prompt. Now, the new output is different, and on the exact same task, it's slightly better.
After repeating this a few times, you convince yourself that the prompt is better than what you started with. However, when you look at it, you realize it's 3x longer than the original. Deep down, you know it still isn't great, but at that point, other priorities take over, and you move on to something supposedly more important.
The issue is that LLMs love producing tokens. They keep extending the prompt based on your feedback, adding some examples here, and DON'Ts and MUST NOTs all over the place. The LLM also starts decompressing itself, spelling out in more words things it obviously already knows. However, this decompression is overfit to the specific cases you iterated on, so it doesn't generalize well to other cases.
The only way out is to actually figure out what you want and why, and write it down precisely yourself, which will often cut the prompt by 90%. It's hard work, and you have to spend real brain cycles distilling all your observations into as few precise words as possible. But I think this is the only way to achieve a great result with an AI-based product for a task that isn't easy to verify or write evals for.
Context Windows Are Limited by Atoms, Not Bits
There is a popular narrative in tech right now: AI progress is exponential, context windows will grow to infinity, and all vertical AI products will soon be replaced by general-purpose AI that can use all the context of your entire business. This implies that the big players like Anthropic, OpenAI, and Google, with their general-purpose agents like Claude Cowork, ChatGPT, or Gemini, will subsume all software.
[... 828 words]10 Years Building Vertical Software: My Perspective on the Selloff. Nicolas Bustamante, who has built vertical software on both sides of the LLM disruption (Doctrine for legal, Fintool for equity research), wrote a moat-by-moat analysis of vertical SaaS that is worth reading. In his view, five moats collapse (learned interfaces, custom workflows, public data access, talent scarcity, and bundling), while five hold (proprietary data, regulatory lock-in, network effects, transaction embedding, and system-of-record status).
A few things I think are missing. The biggest threat to vertical software incumbents probably isn't scrappy AI startups building 80% of the features at 20% of the cost (like his new Fintool company). It's that products like Claude Cowork can do 80% of what vertical software does out of the box, with general agents and data access, at marginal implementation cost. Once integrated, enterprises might trust Anthropic, OpenAI, and Google more than they trust a vibe-coded startup.
There's also a scenario Bustamante doesn't address: LLMs themselves will likely commoditize. If that happens, model providers will have to fight for companies and startups to use their tokens. That's precisely why Anthropic, OpenAI, and Google are strongly pushing into the product space themselves, because products might be more defensible than models. This raises an uncomfortable question for Bustamante's own company, Fintool, which he doesn't address. If what they built is, as he describes, essentially markdown skill files integrating with MCPs and foundation model APIs, what's their justification against the model providers doing the same thing?
Is this where LLMs picked up their famous sycophantic phrase and behavior?
Currently reading Conscious Business by Fred Kofman, a classic on values and authentic communication at work, and stumbled across this on page 57.

On Conscious Business by Fred Kofman
For the first time, you can build a competitive recommender system without a single user.
The playbook behind the flywheel of many of the most powerful companies has been: build a platform, measure engagement data, identify patterns, and make better recommendations to attract more users. That's the network effect that made Google, Meta, and Amazon so hard to compete with.
But LLMs have a compressed representation of that same knowledge from training on vast amounts of the internet. So to overcome the cold-start problem, you no longer need to measure and train on years of engagement data from your own users.
Now you can just give an LLM some context of a user, for example, their social media profile, to get high-quality recommendations. It's a fundamentally different entry point to personalization, one that doesn't depend on scale.
Are LLMs about to break the recommender-system moat?
An Interview with Benedict Evans About AI and Software. Benedict Evans articulates a great insight really well here: LLMs might be a real threat to recommender system moats.
The playbook to build a flywheel has been the following: build a platform, measure engagement data, find patterns, and make better recommendations to attract more users. That's the network effect that made Google, Meta, and Amazon so hard to compete with. But LLMs have a compressed representation of that same knowledge from training on vast amounts of the internet, without having to measure engagement of real users.
To overcome the cold-start problem, you don't need years of engagement data anymore. Now you can just give an LLM some context of a user, for example their social media profile, to get high-quality recommendations. It's a fundamentally different entry point to personalization, one that doesn't depend on scale.
LLMs had a rough start to 2026.
Last week, our AI agent told a user their Monday meeting was on Sunday. The reason? In 2025, January 12th was a Sunday—and that's what the model learned during training.
We're seeing this pattern across many date-related tasks: models confidently inferring the wrong day of the week, or hallucinating years that weren't in the input text.
The obvious fix is to inject today's date into every prompt. However, that's not always what you want. For example, if you're extracting dates from text, adding context about "today" can bias the output and cause hallucinations of its own.
Is this the new Y2K bug we'll have to deal with every January? Or will future models be more robust to year transitions?
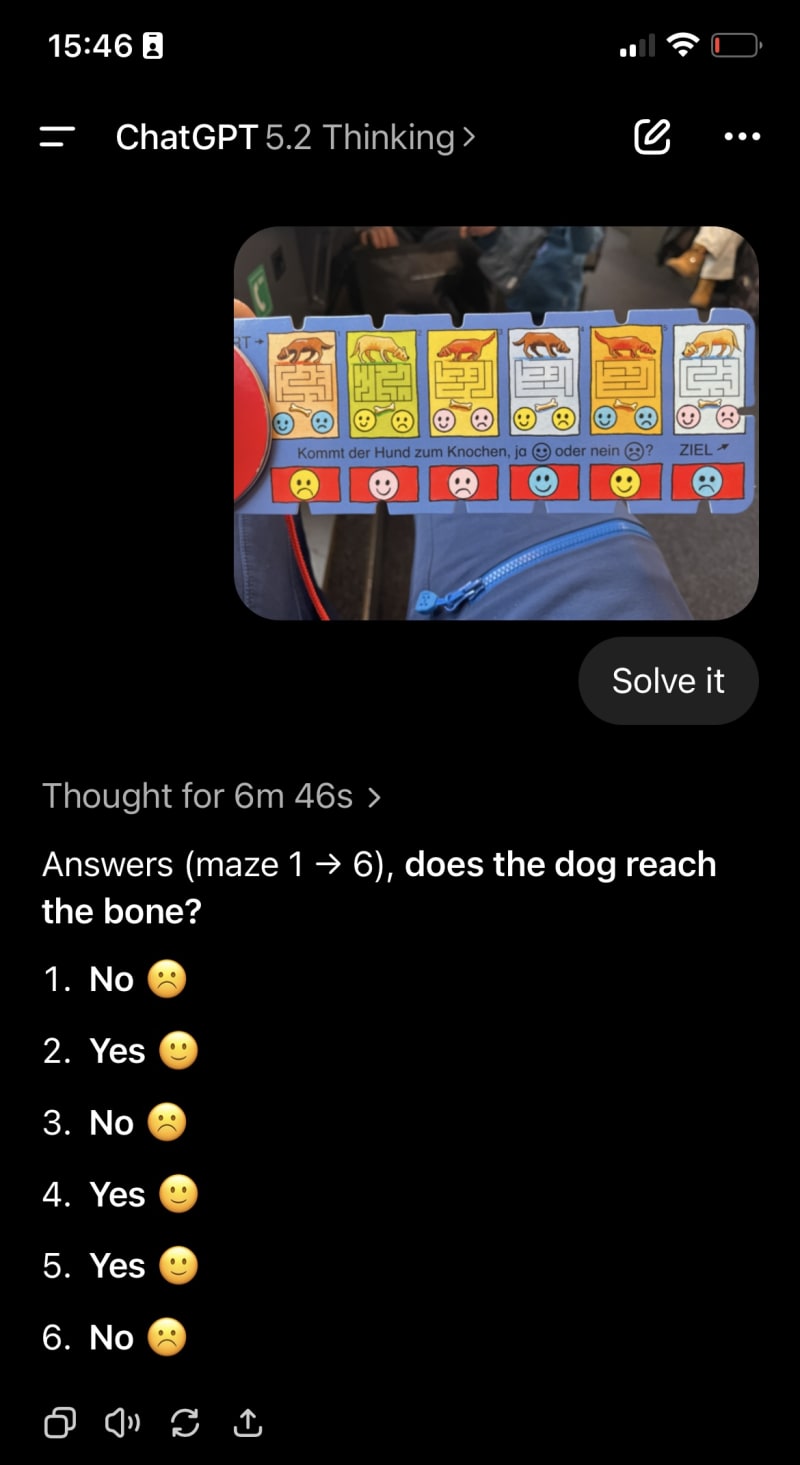
Last weekend, my son was working on a Bandolino puzzle where he had to match questions to answers with a piece of string.
OpenAI just released GPT–5.2 last week, claiming it "performs at or above human expert level" across vision, math, and physics benchmarks [1]. I was curious how long it would take GPT–5.2 to solve it—it failed completely.
How can such a powerful model fail at a task that a four-year-old solved in under a minute after seeing it for the first time?
Andrej Karpathy coined the term "jagged intelligence" for this phenomenon [2]. LLMs can solve complex problems that seem hard to humans while failing at tasks that seem trivially easy. Unlike human intelligence, where abilities tend to correlate and develop together, LLM capabilities are jagged and unpredictable.
To put it another way: while these models are extremely powerful, they can't be trusted.
What does this imply for deploying LLMs in production settings?
(1) Benchmarks give you no guarantees—you have to evaluate models on your own tasks.
(2) Your overall system has to be tolerant of these jagged edges. Use LLMs for the tasks that they are good at and keep a human in the loop on all critical decisions.
(3) You have to take security extremely seriously. Meta's "Agents Rule of Two" is a great framework for AI agent security that is simple to remember and apply in practice [3].
At Ren Systems, we leverage LLMs extensively to create value for our users. But it's always our users who ultimately take action.
What's one lesson you've learned deploying LLMs in production?
(References/links in first comment below)
References/links
[1] Introducing GPT-5.2 – https://openai.com/index/introducing-gpt-5-2/
[2] Andrej Karpathy on jagged intelligence – https://x.com/karpathy/status/1816531576228053133
[3] Meta's Agents Rule of Two – https://ai.meta.com/blog/practical-ai-agent-security/
What the large language models are good at is saying what an answer should sound like, which is different from what an answer should be.