you can outsource your thinking but you cannot outsource your understanding
— yacineMTB, in a tweet that Andrej Karpathy mentioned in his AI Ascent talk “From Vibe Coding to Agentic Engineering”.
Here is something interesting I've learned in the past few weeks about building AI products: AI is not great at writing prompts for itself. It's a trap I've fallen into repeatedly, and I suspect many others have too.
It usually goes like this: You start building a feature that uses one or more prompts for an LLM call, agent, or workflow with a coding agent like Claude Code. The first version works, and the output is ok, but not great. So you show your coding agent some examples and tell it what you don't like, and it edits the prompt. Now, the new output is different, and on the exact same task, it's slightly better.
After repeating this a few times, you convince yourself that the prompt is better than what you started with. However, when you look at it, you realize it's 3x longer than the original. Deep down, you know it still isn't great, but at that point, other priorities take over, and you move on to something supposedly more important.
The issue is that LLMs love producing tokens. They keep extending the prompt based on your feedback, adding some examples here, and DON'Ts and MUST NOTs all over the place. The LLM also starts decompressing itself, spelling out in more words things it obviously already knows. However, this decompression is overfit to the specific cases you iterated on, so it doesn't generalize well to other cases.
The only way out is to actually figure out what you want and why, and write it down precisely yourself, which will often cut the prompt by 90%. It's hard work, and you have to spend real brain cycles distilling all your observations into as few precise words as possible. But I think this is the only way to achieve a great result with an AI-based product for a task that isn't easy to verify or write evals for.
I think that everyone working in AI should build their own agent from scratch, at least once. Not because it's hard, but because it's surprisingly easy, which is precisely the point.
Exactly one year ago today, I read Thorsten Ball's How to Build an Agent, or: The Emperor Has No Clothes. In this blog post, which is the single piece of text that most influenced me last year, he shows how to build a fully functional coding agent from scratch in under 400 lines of code.
Shortly thereafter, we did a one-day hackathon at Ren Systems, and by the end of the day, we had our own working agent running in the terminal. We didn't even use Anthropic's Claude Code back then, so we actually typed the complete agent code manually.
Only after building our own agent did I really start to understand what agents are. I had been reading about agents for months, but something fundamentally different clicked in my brain when I saw our own agent interact with the user, interpret the intent, and iteratively choose the right tools to achieve the goal. This emergent behavior is hard to appreciate without experiencing it so directly.
Agents have become common by now, but I still recommend everyone working in this space to build one from scratch. It sounds almost esoteric, but you have to touch it yourself to really feel what's going on. The moment your agent does something you didn't explicitly program it to do is when the line between deterministic code execution and something that's conscious and thinking starts to blur. You know it's an illusion, but it's a remarkably convincing one.
An AI State of the Union: We’ve Passed the Inflection Point, Dark Factories Are Coming, and Automation Timelines | Simon Willison (Lenny’s Podcast). As someone who follows Simon Willison closely, this interview didn't contain many new ideas for me. But I would still strongly recommend it to anyone who doesn't follow him as closely, because it covers many of his main beliefs and insights in one place, and I consider many of them to be very strong.
The main thing I picked up from the podcast is StrongDM's work on the "dark factory", which Simon covered on his own blog and is definitely worth reading. I have heard the "dark (software) factory" term before and didn't quite understand it, but it is an analogy for manufacturing facilities so automated that the lights are literally turned off because no humans are operating the factory. The core idea of this movement is building development factory in which specs and scenarios drive coding agents to write and review (!) code without humans completely autonomously.
Other things I picked up from this podcast episode: the distinction between agentic engineering and vibe coding, using "red/green TDD" as a micro-prompt to improve coding agent output, and the strategy of building "digital twins" of external services for testing by giving a coding agent just public API docs.
Minions: Stripe’s One-Shot, End-to-End Coding Agents (Stripe Engineering Blog). A fascinating two-part blog post (Part 1, Part 2) from Stripe's engineering team on how they built their internal coding agents, which they call minions. What first stood out to me is how remarkably well-written these posts are. At a time when many engineering blog posts read as if they were mostly AI-generated, a piece with this much clarity is a strong signal of Stripe's commitment to quality in everything they do.
Stripe's minions are fully unattended agents built for one-shot coding tasks. An engineer can kick off a minion from Slack, and it produces a pull request that passes CI and is ready for review, with no human interaction in between. Over a thousand PRs merged per week at Stripe are entirely minion-produced.
As someone working at a startup, I find it fascinating to see this level of investment in what I've been calling "engineering the machine that writes the code". What makes this particularly notable is that Stripe is operating in a very high-stakes environment with high demands on reliability and robustness.
Stripe's system is complex, far beyond what a startup with limited resources could build internally. But what makes it interesting is that minions were built on top of infrastructure Stripe had already developed for human engineers:
We built out devboxes for the needs of human engineers, long before LLM coding agents existed. As it turns out, parallelism, predictability, and isolation were also very desirable properties as well for Stripe engineers to be able to work most effectively. What's good for humans is good for agents, and building on this infrastructural primitive paid dividends as a natural home for LLM agents.
The most interesting technical concept in the post is what they call "blueprints." Anthropic's blog post on building effective agents distinguishes between workflows (fixed execution graphs of LLM calls) and agents (loops with tools). Blueprints are a hybrid: a state machine that interleaves agentic nodes (LLMs or agents can work non-deterministically) with deterministic nodes (e.g., linters, git operations, test runners) that don't invoke an LLM at all. The idea is to put the LLMs in a contained box for each subtask, constraining its tools and context as needed, and guarantee that certain steps always happen correctly.
A few other things stuck with me. Stripe built a centralized internal MCP server, called Toolshed, which hosts nearly 500 tools spanning internal systems and SaaS platforms, and to which all of Stripe's agents can connect. Stripe's engineers also make extensive use of agent rule files that are conditionally applied based on which subdirectory or code files the agent is working in. These rules dynamically provide their coding agents with the necessary context, rather than loading a massive global ruleset, e.g., from a CLAUDE.md file, that would bloat the context window. Notably, all coding at Stripe, whether by humans or agents, happens in sandboxed cloud developer environments called devboxes, which can be spun up in about 10 seconds with all necessary dependencies preloaded.
Our backend engineer, Jan Giacomelli, was inspired by this blog post and just last week built our own internal version: a sandboxed coding agent that one-shots tasks and creates pull requests, which we're calling a "renion." I'm very curious to try it and see where this goes. I'm a strong believer that professional engineering organizations need to engineer their own internal AI systems to some extent, because each company's development environment and requirements are different enough that general tools can't provide maximum value on their own. I'm also curious about how we can bring the "blueprint" pattern of wrapping agents in deterministic workflows to other parts of the AI-powered business logic in our backend.

Vibe coding and agentic engineering are two terms that come up constantly right now, but are often confused. Both describe building software where AI writes most or all of the code, but there is a fundamental difference.
Vibe coding, as Andrej Karpathy originally defined it, means building something without looking at the code. You describe what you want, see if it works, and iterate on the vibes without even intending to read or understand the code.
Agentic engineering is something very different. It's not about writing code with agents, but about engineering a system that uses agents to write code that meets specifications and is well-tested. The resulting code needs to match existing patterns in the codebase, adhere to the company's engineering principles, and pass an extensive test suite.
From what I'm seeing, the best engineering organizations right now are spending a lot of their time on building the machine that writes the code. In practice, this means aligning conventions and patterns throughout the codebase, improving the feedback loop for coding agents, automating review processes, tightening deployment practices, and wrapping LLMs in deterministic workflows.
At Ren Systems, our team has been putting a lot of work into this. Together with Jan Giacomelli and Giorgio Nicoli, we have been working on things like fully typing our test suite, writing custom skills for zero-downtime database migrations, implementing custom linters that deterministically check our desired coding patterns and provide feedback to coding agents when they are violated, and building an AI-assisted code review flow trained on our own review comments from many thousands of past code reviews.
All of this was implemented much more quickly with the help of coding agents, but it required deliberate engineering. As a result, we can now build on our codebase with agents much more quickly, and it is in a much better overall state than it was one year ago.
There is absolutely a place for vibe coding, even for professional developers. It's great for prototyping, exploring ideas, and internal tooling, where the stakes are low, and you're the only person who gets hurt if it has bugs. But this isn't what companies employ professional software engineers for, and that job isn't going away with AI.
If you define software engineering as typing out code by hand, then yes, that job is being replaced. But if you define it as engineering the machine that builds production-grade code, software engineers with these skills are going to be more valuable than ever.
GitLab had 38 public incidents in Q1 2026, up 36% from Q1 2025. March alone had 20, almost one per working day. They even have an active incident as I write this on April 1st, and, sadly, this isn't even an April Fool's joke.
Looking at their status page history, there is a consistent pattern: a code change gets deployed, breaks production, the team identifies the bad MR, and has to revert it. CI/CD pipelines are the most frequently affected component, and the incidents are noticeably impacting our development workflow.
I get it, these things happen to us too. Having to revert bad code changes every now and then is part of working on a complex real-world production system. But what makes this difficult to accept isn't just the trend itself. GitHub's status page is arguably even worse, but at least GitHub appears to be consistently ahead on AI features. GitLab appears to be getting the worst of both worlds: increasing instability without access to the latest capabilities, such as the Claude Code integration. If you're going to break things, you should at least be shipping something valuable and exciting regularly.
I think there's a real question here about whether the industry has crossed a threshold where the speed of shipping with AI tools has outpaced existing deployment systems' ability to catch problems before they reach production. The irony is that GitLab's product is literally about helping teams ship code safely. If the company that builds the CI/CD platform is struggling with this, it might be an early signal that everyone needs to rethink how deployment safety scales when AI dramatically increases the pace of change.
Andrej Karpathy on Code Agents, AutoResearch, and the Loopy Era of AI (No Priors Podcast). Andrej Karpathy is always worth listening to because he has the time to experiment and tinker with the latest developments in a way that most people working at companies don't. He effectively lives a few months in the future compared to the rest of us.
Two things stuck with me from this conversation. First, Karpathy frames Claws (from OpenClaw) as another layer of the AI stack: LLMs → Agents → Claws. I have never actually set up a Claw yet, but the persistent memory architecture and how "your Claw" gets to know you over time are things I want to experiment with, as this is directly relevant to what we're working on at Ren as the product becomes more agentic.
Second, his work on AutoResearch. We've discussed the concept internally at Ren multiple times over the past few months, but never found the time to actually try it. We have a concrete problem that would lend itself well to this approach: building a more efficient multi-label classifier. We currently use a relatively heavy model for it, we have abundant training data, and the objective is clear (maximize precision/recall/F1 for a given latency budget). We could just let an AutoResearch system loose on this task. What I'm missing is knowing how to set up a sandbox that's safe enough but has sufficient permissions for the agent to carry out the research on its own. The meta task would then be similar to Claws: build a system in a few markdown files that defines how the agent approaches and documents its research.
One big danger of AI tools in the workplace is how much easier they make it to pursue side quests.
Side quests used to be self-regulating. You'd think "wouldn't it be cool to try this?", estimate the effort at half a day, and move on. Now you tell yourself "it takes only five minutes", and decide to just go for it out of curiosity, but it's of course never just five minutes.
The result is that you can get to the end of a day having completed ten low-priority items on your todo list very efficiently, while making zero progress on the one high-priority item that needed your attention most. Your only real defense is knowing what the highest-priority item on your list is and holding yourself accountable for making progress on it.
Boris Cherny (creator of Claude Code) on Lenny’s Podcast. I hadn't come across the term "latent demand" before this podcast, and Boris Cherny calls it the single most important principle in product. The idea of latent demand is to watch how users misuse or hack your product to solve their own use cases, and then build specifically for that. Cherny also extends this to AI. With AI products, you should observe what the model/agent is trying to do (e.g., which data it wants to access, which tools are missing, or it has to chain together that could be implemented in a use-case specific tool call), and make that easier.
Cherny also had an interesting comment on innovation. You can't force it, but you have to give people space and psychological safety to fail, but cut ideas that aren't working. Claude Code itself wasn't explicitly on the roadmap, and it wasn't an obvious hit at launch.
He also shared an interesting observation on how roles in and around product are changing with AI. Everyone on the Claude Code team—engineers, PMs, designers, etc.—codes, but with a different angle. He thinks the term "software engineer" might disappear by the end of the year and be replaced by something broader, like "builder".
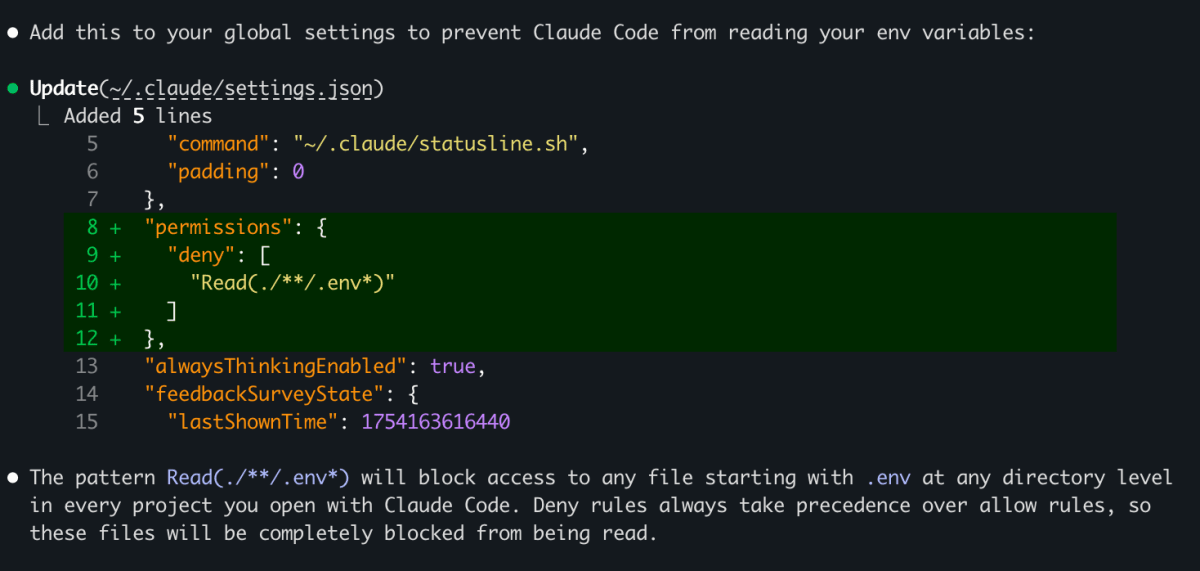
If you're using Claude Code or other coding agents, check whether they have access to your secrets. Many developers assume .env files are protected by default, but they are not.
In Claude Code, the interactive permission prompt is the only barrier, and it's easy to click through without thinking. To fix this, you can add a deny rule in your global Claude Code settings (see screenshot).
It takes 30 seconds to set up, and it's the kind of thing you only think about after something goes wrong.
In my experience, only three things matter for using coding agents effectively:
- Clarity of mind about what you want.
- The ability to put it into words precisely.
- A system to verify the outcome and improve.
The first two are harder than they sound. If you don't know what you want, that's fine, but be conscious of it. Use the agent to gain clarity, don't just let it run when you're still figuring things out.
For the third, give your agent a way to check its own work. A robust feedback loop with type checkers and robust tests turns guessing into learning.
Model choice, prompting tricks, and context management are far less important.
None of this is specific to AI. These are the same skills that make people effective in general: clarity, communication, and the ability to learn from mistakes.
One of the hardest adjustments to AI coding tools has nothing to do with prompting. It's overcoming your attachment to code.
When you write code by hand, you accumulate emotional investment with every line. Throwing it away feels like a waste. So you keep patching, extending, and defending code in reviews that should have been discarded.
Use AI to break this pattern and don't fall into the attachment trap. Code becomes cheap enough to be treated as exploration rather than construction. Prototype quickly, build your mental model, and find the simplest solution that solves your problem. Then start fresh with clarity.
The developers who get the best results aren't the fastest prompters. They're the ones who know when to start over, and when to walk away entirely.
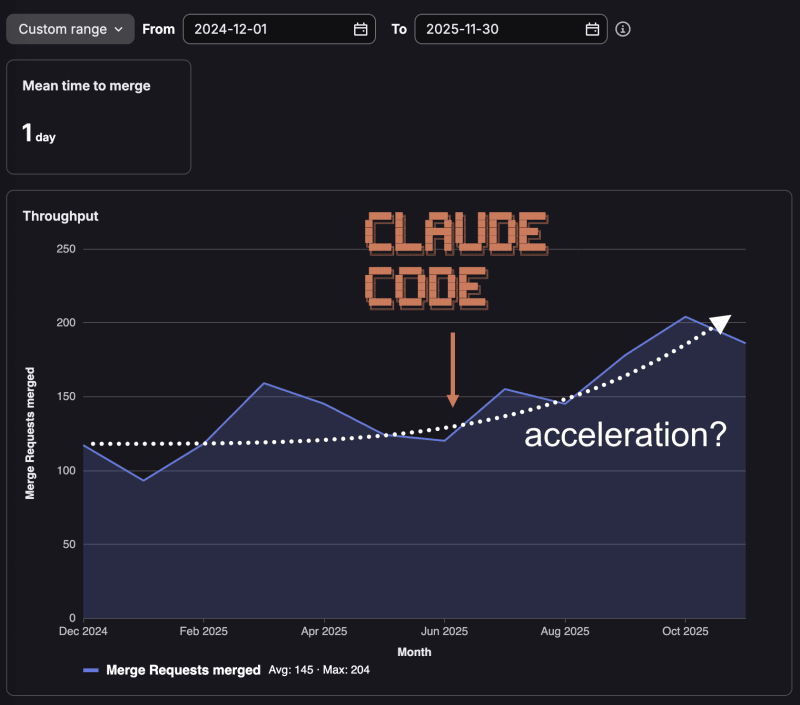
Last week, I posted about AI coding tools and engineering productivity. It got more attention than expected and sparked a debate in comments I didn't anticipate: Is the merge request rate a good measure of productivity?
Fair question. Here's my take:
I used the rate of merged MRs as a proxy metric for productivity. Like all proxies, it's imperfect, but I think it's better than most alternatives, at least in our case.
If you can break a complex feature or refactoring into multiple small, independent MRs, that's not gaming a metric. That's good engineering. Your reviewers will thank you, and your users will benefit. More power to you!
If you're gaming a metric, or worried that others are, the issue isn't the metric. It's your company culture.
So yes, for our company at our current stage, with our team and culture, I believe the rate of merged MRs is a useful signal for engineering velocity.
For what it's worth: at Ren Systems, we don't measure engineers by MR rate or any similar metric. Neither individually, nor collectively. I shared this observation as a quantifiable measure of the acceleration we feel as a team in our daily work.
But this debate is secondary to my main point: I wasn't claiming AI made us magically faster. The observation was that our merge rate increased. The argument was that strong foundations are the reason we're accelerating.
Are AI tools contributing? Probably. But they're not the cause. They're the amplifier.
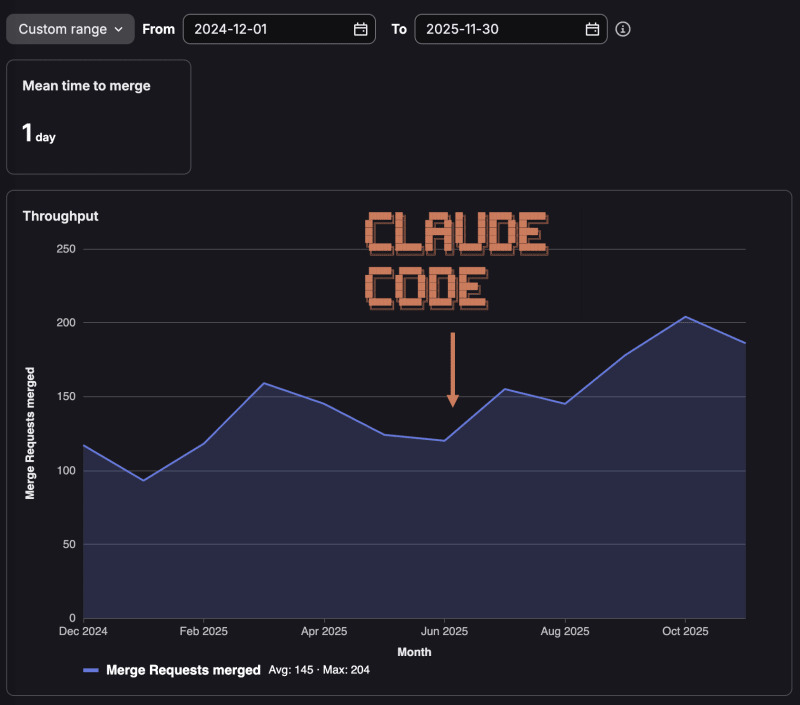
Since our engineering team adopted Anthropic's Claude Code in June, we're shipping code to production over 50% faster.
Do AI coding tools make developers more productive or is it all hype? I think that's the wrong question. The real question is: do you have the foundation to use them well?
Teams with solid architecture, test harnesses, and reliable CI/CD are accelerating. Teams without those fundamentals are drowning in code they can't trust.
At Ren Systems, our engineering team spent years building those foundations, thanks to the hard work of people like Jan Giacomelli and Giorgio Nicoli. Now that investment is compounding.
Have AI coding tools made us 10x more productive? No. But we're shipping more, with confidence, and nobody's losing sleep. Features that used to take months now ship in days. Our Salesforce integration, on our sales team's wishlist for years, took one week to build.
AI coding tools don't replace good engineering. They amplify whatever's already there.