May 2026
5 posts: 1 link, 1 quote, 3 notes
you can outsource your thinking but you cannot outsource your understanding
— yacineMTB, in a tweet that Andrej Karpathy mentioned in his AI Ascent talk “From Vibe Coding to Agentic Engineering”.
Appearing Productive in The Workplace. A nuanced, well-written blog post on the dangers of using AI in the workplace.
The author identifies two distinct failure modes:
Generative AI can produce work that looks expert without being expert, and the failure arrives in two shapes. The first is when novices in a field are able to produce work that resembles what their seniors produce, faster or more advanced than their judgment. The second is when people generate artifacts in disciplines they were never trained in.
Another interesting observation is on workslop, now that the cost of producing a document has fallen to nearly zero:
Requirements documents that were once a page are now twelve. Status updates that were once three sentences are now bulleted summaries of bulleted summaries. Retrospective notes, post-incident reports, design memos, kickoff decks: every artifact that can be elongated is, by people who do not read what they produce, for readers who do not read what they receive.
The author also writes about the implications for companies, which is a view I share:
For firms, the competitive advantage of a firm whose work can be trusted has not disappeared; it has, if anything, appreciated, because so many of the firm’s competitors are quietly converting themselves into content-generation pipelines and counting on the client not to notice.
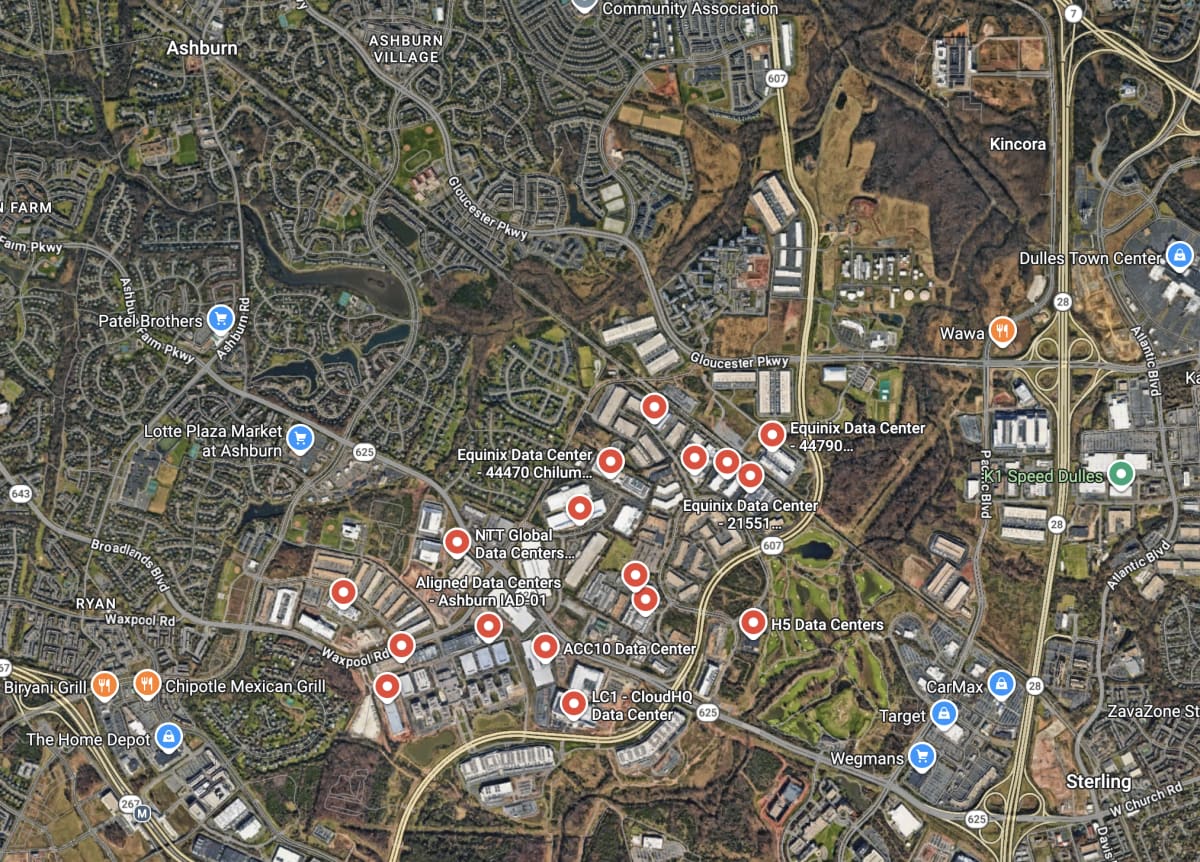
Have you ever wondered what “the cloud” actually looks like? It’s a lot more physical than it sounds.
This Google Maps screenshot shows the so-called “Data Center Alley” in Ashburn, Northern Virginia—a cluster of warehouse-sized data centers located between a golf course and a few suburbs that look like they’re straight out of an American movie. AWS’s famous us-east-1 lives here, along with data centers from Microsoft, Google, Meta, IBM, Oracle, and many others. According to a frequently cited estimate from the local economic development office, around 70% of the world’s internet traffic passes through here. I have some doubts about whether this estimate is still accurate, but it is likely the world’s largest concentration of digital infrastructure.
As a software engineer or AI builder, it’s easy to forget that whatever services you call or build on, your code is actually moving photons through optical fibers and electrons across silicon somewhere, drawing real power from an electrical grid. AI is progressing really quickly right now, but the underlying physical infrastructure imposes constraints on how much of that progress is actually deployable.
If you're still using BERT-style token classification models for NER tagging in production, you should probably reevaluate.
Last summer, we replaced our token classification model with Google's Gemini 2.5 Flash Lite for NER tagging people, companies, and locations on millions of news articles per day. At first, it felt wrong and overkill to replace a well-established, standard approach with a generative model. However, on our own evaluation datasets, the LLM outperformed every BERT model we had implemented previously because it brings so much more contextual understanding to the task.
There are a few obvious advantages to using LLMs for NER tagging. For example, LLMs can easily handle text like "Michael and Jennifer Smith" and correctly extract both "Michael Smith" and "Jennifer Smith" as separate people. They are also much better at handling formatting issues and messy edge cases you inevitably encounter in real-world data at scale.
Deployment is also dramatically simpler: instead of managing model serving infrastructure, you're calling an inference API that you can parallelize and scale easily. Additionally, you automatically benefit from LLMs getting better and cheaper over time without changing anything on your end, provided that you have a solid eval dataset.
We're now processing close to 1B input tokens and producing 100M output tokens per day on this pipeline alone. The most popular pre-trained NER models on Hugging Face are still downloaded millions of times per month, which tells me that structured text extraction with LLMs is one of the most underrated applications right now.
Dependency cooldowns are a highly effective way to mitigate supply-chain attacks, which have become a lot more frequent recently. And because it’s such a simple strategy to implement, I think that every project should adopt it.
Once a malicious release of a popular package is published, the attacker’s window of opportunity is usually less than a week before it’s detected. Therefore, as William Woodruff showed, adding a one- or two-week cooldown period before adopting any new release would have prevented most of the prominent supply-chain attacks in recent months.
Implementation in uv for Python is as simple as adding this one line to your pyproject.toml:
toml
exclude-newer = "1 week"
Dependabot, Renovate, and pnpm all have equivalent features.
One common pushback against this strategy is that it stops working if everyone adopts it, but I don’t think this is correct. Compromised releases get caught quickly, not because they are used in a real exploit first, but because there are researchers actively looking for them.
Dependency cooldowns, of course, don’t catch all supply-chain attacks, but for a one-line config change, they offer a lot of protection.