Taste and judgment have become the new buzzwords of the product world. Everyone agrees they matter more than ever, but I’ve rarely seen anyone define them precisely. So here’s my attempt, in computer science terms.
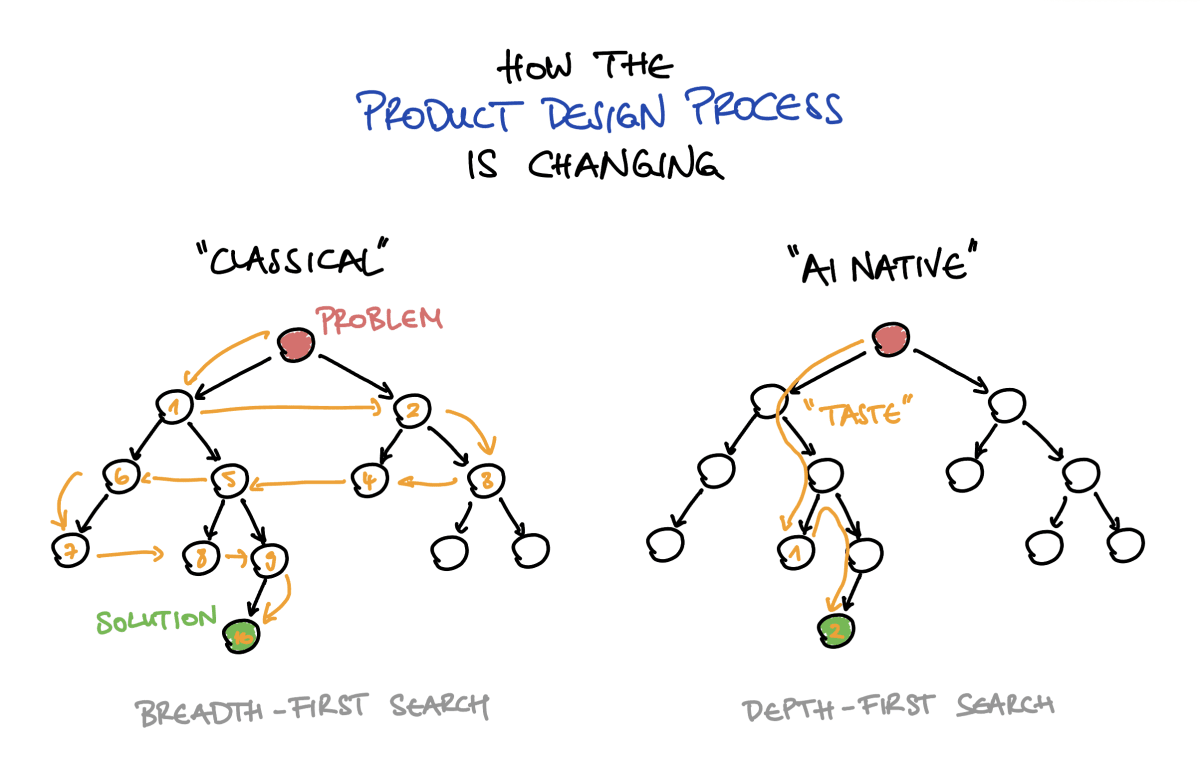
The classical product design process is a breadth-first search. You extensively map the problem space, interview a lot of users, explore many directions with low-fidelity prototypes, and only commit to one solution late. The process is deliberately systematic, which means it protects you from your own bad intuitions and biases by exploring the whole decision tree. It guides the search for you, at the cost of speed.
With AI, the process is becoming a depth-first search. Now you can go from a rough idea to a production-looking prototype in a few hours, effectively committing to one branch of the tree without ever having explored the others. Taste or judgment, then, is the ability to intuitively direct that depth-first search. It’s picking the right branch early, sensing when a path is a dead end, and knowing when to backtrack instead of digging deeper. Someone with great early judgment finds the solution in a fraction of the time. But if, and only if, their early decisions are right a lot more often than not.
The goal isn’t to skip the classical work. User research still matters, but I think that you can learn much faster from a working prototype than from an abstract discovery phase. Therefore, you can use the same activities in a more directed way and with a larger step size per iteration.
The danger is that every artifact generated with AI looks finished because it produces polished prototypes by default. Before, a prototype earned its polish through deliberate human effort, so its looks told you something about how well the underlying idea had been worked out. Because this signal is now gone, we have to communicate much more explicitly where in the design process a prototype sits.
I think the people who will thrive in the new process are product managers and designers who can also build, and experienced engineers with real product and business sense. Both can traverse the tree quickly, and most importantly, have the judgment to save a lot of time by being directionally right in many of their early decisions.
I have used MCP servers every now and then in the past, but they have never saved me much time. Last week, however, I got real value out of them for the first time, and I want to share what I learned.
Using an MCP integration as a “glorified form-filling tool” for a service that already offers a purpose-built UI can be useful, but in my experience, it doesn’t meaningfully increase productivity. Instead, the key insight was to use not one but two MCP servers, from entirely different systems that were never designed to communicate, and to use the LLM to connect them.
In my case, I used the Mixpanel and Notion MCP connectors, together with Claude, to build new analytics dashboards in Mixpanel, based on the extensive documentation I had previously written in Notion about our analytics and new onboarding flow. That documentation, together with the implementation tickets, gave Claude enough context to build exactly the dashboards I needed, from only a clear but high-level description of what I wanted. The resulting dashboards only required minimal manual adjustments from me.
I came to see that MCP integrations are not really about interacting with a server in natural language. They’re the piping that an LLM can use to connect or glue together deterministic systems that weren’t designed to talk to each other. And the more services you can wire together in a useful way, the more value they can provide.
For this reason, they are a great tool for prototyping and for producing any stateful output or asset that can be reviewed and refined before it is used or shared. However, I’m a lot less convinced they’ll be useful for building enterprise workflows that automate business processes and need to be robust. At least to date, MCP servers can easily have breaking changes, aren’t versioned, and so on. And the more MCP servers are involved, the more fragile any workflow becomes.
Lastly, my practical advice for the product engineers tasked with building an MCP server is not to think of it as a wrapper around your API, but to ask yourself how to build an interface for your service that is maximally useful when combined with any other existing service, to enable unique and custom use cases for the user.
[…] if reading this wasn’t worth your time, why is it worth mine?
Therefore, I’ve adopted this principle in my work:
If you are requesting human attention, demonstrate human effort.
— Tom Bedor, On the practice of sending unsolicited AI slop to colleagues.
Anthropic announced two weeks ago that its run-rate revenue crossed $47 billion. With most of the coverage focusing on numbers like these, it’s easy to forget the companies that are sitting on the other side of this bill, actually spending all this money on tokens.
To put the number in perspective, Anthropic’s current run-rate revenue alone is roughly half the size of the entire global CRM market. Together with others like OpenAI and the AI revenue flowing through Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, the total token spend is approaching the size of software categories like CRM and ERP systems that took decades to mature.
Almost every company agrees it needs some form of CRM or ERP system, and no one has to justify the existence of that line item. For AI, however, the case is much less settled, and CFOs are now demanding to see ROI on token spend, which can be genuinely hard to measure or attribute with general-purpose tools like Claude or ChatGPT.
On top of that, current changes to pricing models make budgeting and buying decisions even harder for enterprises. In a Stratechery interview last week, Satya Nadella described the future of software pricing as hybrid, combining a per-user model with a consumption model, because “there is real marginal cost to software” now, and that cost will be priced through. But enterprises are used to per-seat licenses and like them precisely because they are predictable. Ironically, many vendors are now moving toward usage-based pricing to control their own costs, just as buyers are asking for predictability.
Therefore, I doubt that frontier-lab revenue will continue to grow as steeply as it has over the past few months, and we might reach a temporary plateau due to uncertainty. I am convinced that this presents an opportunity for startups offering purpose-built AI systems focused on solving specific business problems, with a much more predictable pricing model and cost structure.
I know that the following is very unscientific and just "vibes," but in my personal experience, Anthropic's models have severely degraded since shortly before Opus 4.7 was released about six weeks ago. And my initial impression from the week or so I've spent with 4.8 is that it isn't any better.
Three months ago, Opus 4.6 was great and highly reliable. However, the performance of the recent 4.7 and 4.8 models is much less reliable for me. They often think for a long time before suddenly speeding up and answering suspiciously quickly. I now also frequently see the model correct itself in the final answer, as if it hadn't already settled on its answer during the reasoning tokens. And the models seem to lose context even in short conversations of no more than a few thousand tokens. For a while, I switched to the Opus 4.6 1M context window model instead of 4.7, but I feel that 4.6 has also degraded in recent weeks, as surprising as that may sound.
I'm reminded of the time around March/April, when Anthropic admitted that a few changes to the Claude Code harness had degraded its performance. According to their postmortem, the bugs were in the harness, not the model weights or the API. But this time, I don't think it's only the Claude Code harness, because I'm seeing the same problems in the Claude desktop app. Yesterday I asked Opus 4.8 to write some SQL queries for an investigation, a task I've done almost daily for well over a year. I usually provide the table schemas and indices, and the models normally write long, complex queries based on my instructions without trouble. This time, it just wouldn't understand what I needed, and I had to be far more explicit than ever before, even though it was a relatively simple task.
I wonder whether it's quantization or context compaction because of Anthropic's compute crunch, or whether the models have been overtrained on benchmarks with very clear task descriptions. But I need models to read between the lines and remember the context of a conversation. Otherwise, I might as well write the SQL query, code, or text myself if I have to be very explicit. I haven't tried any serious workloads on local models yet, and I'm sure I'd be even more frustrated than with the latest Opus models.
The crazy thing is that I don't want the models to be bad. I'd much rather write about the cool things I'm building with them than about how they've regressed. I genuinely want Anthropic models to be good, and the most frustrating part is knowing they were great just a few months ago, but having no way to access them now.
If you're still using BERT-style token classification models for NER tagging in production, you should probably reevaluate.
Last summer, we replaced our token classification model with Google's Gemini 2.5 Flash Lite for NER tagging people, companies, and locations on millions of news articles per day. At first, it felt wrong and overkill to replace a well-established, standard approach with a generative model. However, on our own evaluation datasets, the LLM outperformed every BERT model we had implemented previously because it brings so much more contextual understanding to the task.
There are a few obvious advantages to using LLMs for NER tagging. For example, LLMs can easily handle text like "Michael and Jennifer Smith" and correctly extract both "Michael Smith" and "Jennifer Smith" as separate people. They are also much better at handling formatting issues and messy edge cases you inevitably encounter in real-world data at scale.
Deployment is also dramatically simpler: instead of managing model serving infrastructure, you're calling an inference API that you can parallelize and scale easily. Additionally, you automatically benefit from LLMs getting better and cheaper over time without changing anything on your end, provided that you have a solid eval dataset.
We're now processing close to 1B input tokens and producing 100M output tokens per day on this pipeline alone. The most popular pre-trained NER models on Hugging Face are still downloaded millions of times per month, which tells me that structured text extraction with LLMs is one of the most underrated applications right now.
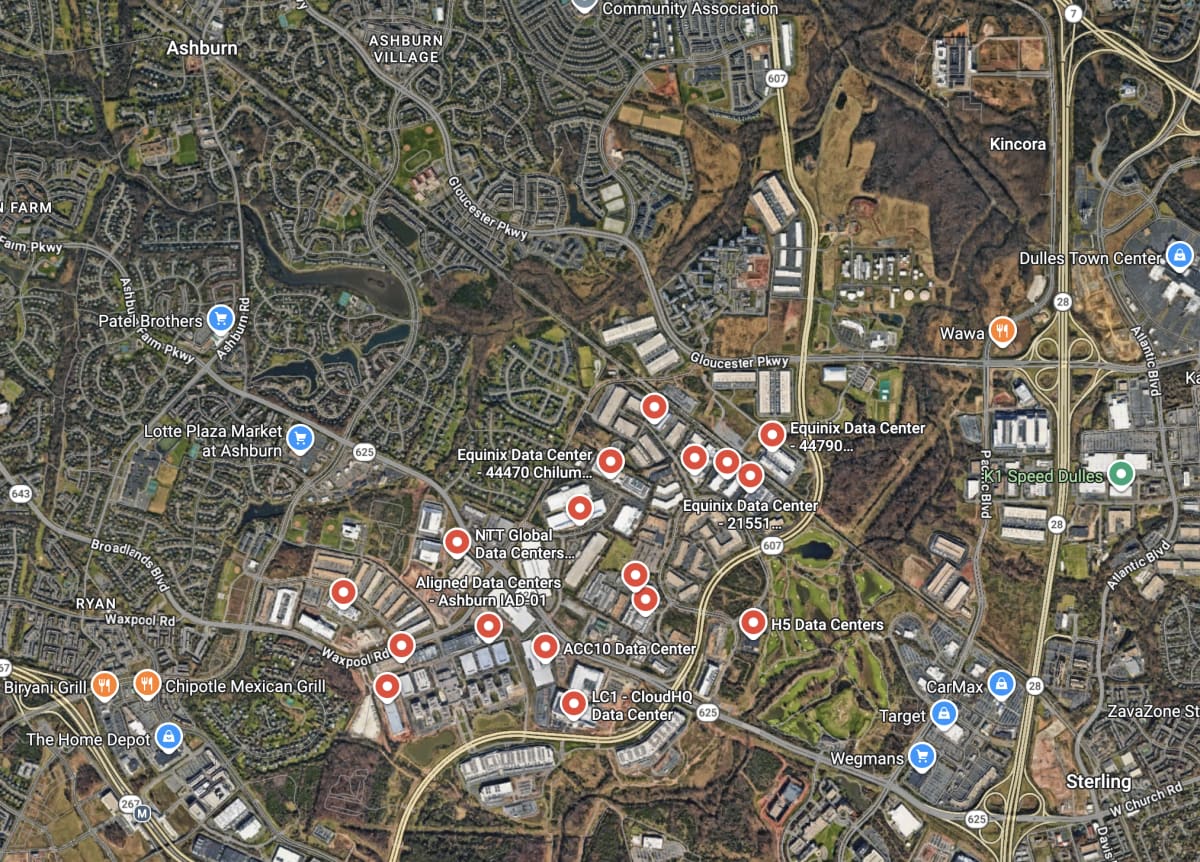
Have you ever wondered what “the cloud” actually looks like? It’s a lot more physical than it sounds.
This Google Maps screenshot shows the so-called “Data Center Alley” in Ashburn, Northern Virginia—a cluster of warehouse-sized data centers located between a golf course and a few suburbs that look like they’re straight out of an American movie. AWS’s famous us-east-1 lives here, along with data centers from Microsoft, Google, Meta, IBM, Oracle, and many others. According to a frequently cited estimate from the local economic development office, around 70% of the world’s internet traffic passes through here. I have some doubts about whether this estimate is still accurate, but it is likely the world’s largest concentration of digital infrastructure.
As a software engineer or AI builder, it’s easy to forget that whatever services you call or build on, your code is actually moving photons through optical fibers and electrons across silicon somewhere, drawing real power from an electrical grid. AI is progressing really quickly right now, but the underlying physical infrastructure imposes constraints on how much of that progress is actually deployable.
Appearing Productive in The Workplace. A nuanced, well-written blog post on the dangers of using AI in the workplace.
The author identifies two distinct failure modes:
Generative AI can produce work that looks expert without being expert, and the failure arrives in two shapes. The first is when novices in a field are able to produce work that resembles what their seniors produce, faster or more advanced than their judgment. The second is when people generate artifacts in disciplines they were never trained in.
Another interesting observation is on workslop, now that the cost of producing a document has fallen to nearly zero:
Requirements documents that were once a page are now twelve. Status updates that were once three sentences are now bulleted summaries of bulleted summaries. Retrospective notes, post-incident reports, design memos, kickoff decks: every artifact that can be elongated is, by people who do not read what they produce, for readers who do not read what they receive.
The author also writes about the implications for companies, which is a view I share:
For firms, the competitive advantage of a firm whose work can be trusted has not disappeared; it has, if anything, appreciated, because so many of the firm’s competitors are quietly converting themselves into content-generation pipelines and counting on the client not to notice.
you can outsource your thinking but you cannot outsource your understanding
— yacineMTB, in a tweet that Andrej Karpathy mentioned in his AI Ascent talk “From Vibe Coding to Agentic Engineering”.
Here is something interesting I've learned in the past few weeks about building AI products: AI is not great at writing prompts for itself. It's a trap I've fallen into repeatedly, and I suspect many others have too.
It usually goes like this: You start building a feature that uses one or more prompts for an LLM call, agent, or workflow with a coding agent like Claude Code. The first version works, and the output is ok, but not great. So you show your coding agent some examples and tell it what you don't like, and it edits the prompt. Now, the new output is different, and on the exact same task, it's slightly better.
After repeating this a few times, you convince yourself that the prompt is better than what you started with. However, when you look at it, you realize it's 3x longer than the original. Deep down, you know it still isn't great, but at that point, other priorities take over, and you move on to something supposedly more important.
The issue is that LLMs love producing tokens. They keep extending the prompt based on your feedback, adding some examples here, and DON'Ts and MUST NOTs all over the place. The LLM also starts decompressing itself, spelling out in more words things it obviously already knows. However, this decompression is overfit to the specific cases you iterated on, so it doesn't generalize well to other cases.
The only way out is to actually figure out what you want and why, and write it down precisely yourself, which will often cut the prompt by 90%. It's hard work, and you have to spend real brain cycles distilling all your observations into as few precise words as possible. But I think this is the only way to achieve a great result with an AI-based product for a task that isn't easy to verify or write evals for.
I think that everyone working in AI should build their own agent from scratch, at least once. Not because it's hard, but because it's surprisingly easy, which is precisely the point.
Exactly one year ago today, I read Thorsten Ball's How to Build an Agent, or: The Emperor Has No Clothes. In this blog post, which is the single piece of text that most influenced me last year, he shows how to build a fully functional coding agent from scratch in under 400 lines of code.
Shortly thereafter, we did a one-day hackathon at Ren Systems, and by the end of the day, we had our own working agent running in the terminal. We didn't even use Anthropic's Claude Code back then, so we actually typed the complete agent code manually.
Only after building our own agent did I really start to understand what agents are. I had been reading about agents for months, but something fundamentally different clicked in my brain when I saw our own agent interact with the user, interpret the intent, and iteratively choose the right tools to achieve the goal. This emergent behavior is hard to appreciate without experiencing it so directly.
Agents have become common by now, but I still recommend everyone working in this space to build one from scratch. It sounds almost esoteric, but you have to touch it yourself to really feel what's going on. The moment your agent does something you didn't explicitly program it to do is when the line between deterministic code execution and something that's conscious and thinking starts to blur. You know it's an illusion, but it's a remarkably convincing one.
An AI State of the Union: We’ve Passed the Inflection Point, Dark Factories Are Coming, and Automation Timelines | Simon Willison (Lenny’s Podcast). As someone who follows Simon Willison closely, this interview didn't contain many new ideas for me. But I would still strongly recommend it to anyone who doesn't follow him as closely, because it covers many of his main beliefs and insights in one place, and I consider many of them to be very strong.
The main thing I picked up from the podcast is StrongDM's work on the "dark factory", which Simon covered on his own blog and is definitely worth reading. I have heard the "dark (software) factory" term before and didn't quite understand it, but it is an analogy for manufacturing facilities so automated that the lights are literally turned off because no humans are operating the factory. The core idea of this movement is building development factory in which specs and scenarios drive coding agents to write and review (!) code without humans completely autonomously.
Other things I picked up from this podcast episode: the distinction between agentic engineering and vibe coding, using "red/green TDD" as a micro-prompt to improve coding agent output, and the strategy of building "digital twins" of external services for testing by giving a coding agent just public API docs.
Minions: Stripe’s One-Shot, End-to-End Coding Agents (Stripe Engineering Blog). A fascinating two-part blog post (Part 1, Part 2) from Stripe's engineering team on how they built their internal coding agents, which they call minions. What first stood out to me is how remarkably well-written these posts are. At a time when many engineering blog posts read as if they were mostly AI-generated, a piece with this much clarity is a strong signal of Stripe's commitment to quality in everything they do.
Stripe's minions are fully unattended agents built for one-shot coding tasks. An engineer can kick off a minion from Slack, and it produces a pull request that passes CI and is ready for review, with no human interaction in between. Over a thousand PRs merged per week at Stripe are entirely minion-produced.
As someone working at a startup, I find it fascinating to see this level of investment in what I've been calling "engineering the machine that writes the code". What makes this particularly notable is that Stripe is operating in a very high-stakes environment with high demands on reliability and robustness.
Stripe's system is complex, far beyond what a startup with limited resources could build internally. But what makes it interesting is that minions were built on top of infrastructure Stripe had already developed for human engineers:
We built out devboxes for the needs of human engineers, long before LLM coding agents existed. As it turns out, parallelism, predictability, and isolation were also very desirable properties as well for Stripe engineers to be able to work most effectively. What's good for humans is good for agents, and building on this infrastructural primitive paid dividends as a natural home for LLM agents.
The most interesting technical concept in the post is what they call "blueprints." Anthropic's blog post on building effective agents distinguishes between workflows (fixed execution graphs of LLM calls) and agents (loops with tools). Blueprints are a hybrid: a state machine that interleaves agentic nodes (LLMs or agents can work non-deterministically) with deterministic nodes (e.g., linters, git operations, test runners) that don't invoke an LLM at all. The idea is to put the LLMs in a contained box for each subtask, constraining its tools and context as needed, and guarantee that certain steps always happen correctly.
A few other things stuck with me. Stripe built a centralized internal MCP server, called Toolshed, which hosts nearly 500 tools spanning internal systems and SaaS platforms, and to which all of Stripe's agents can connect. Stripe's engineers also make extensive use of agent rule files that are conditionally applied based on which subdirectory or code files the agent is working in. These rules dynamically provide their coding agents with the necessary context, rather than loading a massive global ruleset, e.g., from a CLAUDE.md file, that would bloat the context window. Notably, all coding at Stripe, whether by humans or agents, happens in sandboxed cloud developer environments called devboxes, which can be spun up in about 10 seconds with all necessary dependencies preloaded.
Our backend engineer, Jan Giacomelli, was inspired by this blog post and just last week built our own internal version: a sandboxed coding agent that one-shots tasks and creates pull requests, which we're calling a "renion." I'm very curious to try it and see where this goes. I'm a strong believer that professional engineering organizations need to engineer their own internal AI systems to some extent, because each company's development environment and requirements are different enough that general tools can't provide maximum value on their own. I'm also curious about how we can bring the "blueprint" pattern of wrapping agents in deterministic workflows to other parts of the AI-powered business logic in our backend.

Vibe coding and agentic engineering are two terms that come up constantly right now, but are often confused. Both describe building software where AI writes most or all of the code, but there is a fundamental difference.
Vibe coding, as Andrej Karpathy originally defined it, means building something without looking at the code. You describe what you want, see if it works, and iterate on the vibes without even intending to read or understand the code.
Agentic engineering is something very different. It's not about writing code with agents, but about engineering a system that uses agents to write code that meets specifications and is well-tested. The resulting code needs to match existing patterns in the codebase, adhere to the company's engineering principles, and pass an extensive test suite.
From what I'm seeing, the best engineering organizations right now are spending a lot of their time on building the machine that writes the code. In practice, this means aligning conventions and patterns throughout the codebase, improving the feedback loop for coding agents, automating review processes, tightening deployment practices, and wrapping LLMs in deterministic workflows.
At Ren Systems, our team has been putting a lot of work into this. Together with Jan Giacomelli and Giorgio Nicoli, we have been working on things like fully typing our test suite, writing custom skills for zero-downtime database migrations, implementing custom linters that deterministically check our desired coding patterns and provide feedback to coding agents when they are violated, and building an AI-assisted code review flow trained on our own review comments from many thousands of past code reviews.
All of this was implemented much more quickly with the help of coding agents, but it required deliberate engineering. As a result, we can now build on our codebase with agents much more quickly, and it is in a much better overall state than it was one year ago.
There is absolutely a place for vibe coding, even for professional developers. It's great for prototyping, exploring ideas, and internal tooling, where the stakes are low, and you're the only person who gets hurt if it has bugs. But this isn't what companies employ professional software engineers for, and that job isn't going away with AI.
If you define software engineering as typing out code by hand, then yes, that job is being replaced. But if you define it as engineering the machine that builds production-grade code, software engineers with these skills are going to be more valuable than ever.
An Interview with Asymco’s Horace Dediu About Apple at 50 (Stratechery). Horace Dediu, who has worked closely with Clay Christensen, makes an interesting point in this interview about why, in his view, AI is a sustaining technology for the big incumbents rather than a disruption. Google, Microsoft, Meta, and Amazon are all pouring hundreds of billions into AI instead of being repelled by it and thinking "this isn't for us" or "our customers don't want this". So obviously they all think that AI is a sustaining technology for them.
The interesting exception is Apple, which is the only major tech company that, unlike most others, isn't sprinting to spend as much as possible on AI infrastructure. In Horace Dediu's view, Apple has always positioned itself at the interface between humans and computers, and thinks that the current AI interface (essentially a command line for natural language) isn't where they'd want to compete. Whether Apple is making a smart strategic bet by waiting for the technology to commoditize and then controlling the device and interface layer, or whether they're the one incumbent that actually is being disrupted, is the open question.
GitLab had 38 public incidents in Q1 2026, up 36% from Q1 2025. March alone had 20, almost one per working day. They even have an active incident as I write this on April 1st, and, sadly, this isn't even an April Fool's joke.
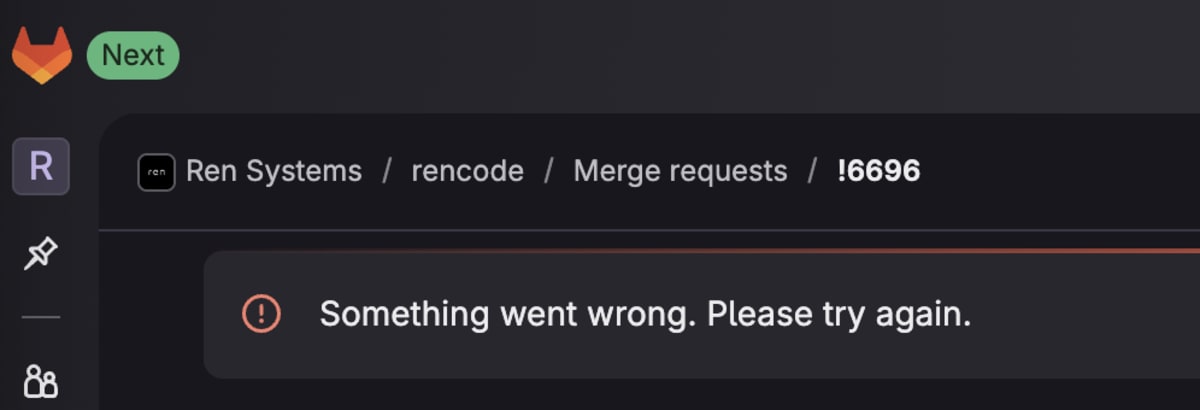
Looking at their status page history, there is a consistent pattern: a code change gets deployed, breaks production, the team identifies the bad MR, and has to revert it. CI/CD pipelines are the most frequently affected component, and the incidents are noticeably impacting our development workflow.
I get it, these things happen to us too. Having to revert bad code changes every now and then is part of working on a complex real-world production system. But what makes this difficult to accept isn't just the trend itself. GitHub's status page is arguably even worse, but at least GitHub appears to be consistently ahead on AI features. GitLab appears to be getting the worst of both worlds: increasing instability without access to the latest capabilities, such as the Claude Code integration. If you're going to break things, you should at least be shipping something valuable and exciting regularly.
I think there's a real question here about whether the industry has crossed a threshold where the speed of shipping with AI tools has outpaced existing deployment systems' ability to catch problems before they reach production. The irony is that GitLab's product is literally about helping teams ship code safely. If the company that builds the CI/CD platform is struggling with this, it might be an early signal that everyone needs to rethink how deployment safety scales when AI dramatically increases the pace of change.
From skeptic to true believer: How OpenClaw changed my life (Lenny’s Podcast). This is the podcast on OpenClaw I listened to this weekend after the Karpathy episode. I think I understood the appeal of a proactive system that works independently from the start, but I haven't bought into the hype so far. However, I feel that these two podcasts together have started changing my mind—not because of a single capability, but because of the apparent emergent behavior that arises once a Claw has context about you and access to real tools. Agents, as we typically think of them, are reactive: you give them a task, and they execute what they are asked to do. But I now fully realize that Claws are persistent and have personalities of their own. They run in the background, build up memory over time, check in on a schedule, and start acting on your behalf without being prompted.
Claire Vo, who was apparently a big OpenClaw skeptic when it launched, now manages nine agents across multiple Mac Minis for both personal and professional use.
The first thing that stood out to me in this conversation is how well the onboarding is apparently done. Instead of structured forms and settings pages, your Claw just asks you who it is and who you are, and you figure it out together through conversation, as if you hired a new employee. The second thing I learned is how well-crafted the default behavior of the Claw appears to be. The Claw's behavior emerges from some simple markdown files ("soul document"), but the defaults are apparently surprisingly thoughtful and lead to a really pleasant behavior. It sounds like this is something anyone working in product right now should experience firsthand.
I'm now genuinely intrigued to try it myself. To really get the full experience, you clearly need to run it on a separate machine, both for security and because you don't want to think about whether your laptop is online. I should really try setting one up on my Raspberry Pi, or just buy a Mac Mini for it. The other thing I don't really have yet is a clear use case for a Claw. I wonder whether I should try to come up with one before getting started, or whether this is something you just have to go for, because the onboarding seems good enough that the use case will emerge during the setup process.
Andrej Karpathy on Code Agents, AutoResearch, and the Loopy Era of AI (No Priors Podcast). Andrej Karpathy is always worth listening to because he has the time to experiment and tinker with the latest developments in a way that most people working at companies don't. He effectively lives a few months in the future compared to the rest of us.
Two things stuck with me from this conversation. First, Karpathy frames Claws (from OpenClaw) as another layer of the AI stack: LLMs → Agents → Claws. I have never actually set up a Claw yet, but the persistent memory architecture and how "your Claw" gets to know you over time are things I want to experiment with, as this is directly relevant to what we're working on at Ren as the product becomes more agentic.
Second, his work on AutoResearch. We've discussed the concept internally at Ren multiple times over the past few months, but never found the time to actually try it. We have a concrete problem that would lend itself well to this approach: building a more efficient multi-label classifier. We currently use a relatively heavy model for it, we have abundant training data, and the objective is clear (maximize precision/recall/F1 for a given latency budget). We could just let an AutoResearch system loose on this task. What I'm missing is knowing how to set up a sandbox that's safe enough but has sufficient permissions for the agent to carry out the research on its own. The meta task would then be similar to Claws: build a system in a few markdown files that defines how the agent approaches and documents its research.
One big danger of AI tools in the workplace is how much easier they make it to pursue side quests.
Side quests used to be self-regulating. You'd think "wouldn't it be cool to try this?", estimate the effort at half a day, and move on. Now you tell yourself "it takes only five minutes", and decide to just go for it out of curiosity, but it's of course never just five minutes.
The result is that you can get to the end of a day having completed ten low-priority items on your todo list very efficiently, while making zero progress on the one high-priority item that needed your attention most. Your only real defense is knowing what the highest-priority item on your list is and holding yourself accountable for making progress on it.
The reason why Nvidia can move so fast is because we always have a unifying theory for the company, which is my job [as the CEO of the company]. I need to come up with a unifying theory for what's important and why things connect together and how they connect together and then create an organization, an organism that's really, really good at delivering on that unifying theory.
— Jensen Huang, Stratechery interview with Nvidia CEO Jensen Huang
Em-dashes have become a telltale sign of AI-generated text, which has created some funny side effects.
I now frequently see correct and incorrect usage of hyphens and dashes mixed in the same piece of text. This happens when someone revises a piece of AI-generated text but doesn't understand the difference between hyphens, en-dashes, and em-dashes.
It's also pretty obvious that some people have started find-replacing all em-dashes with single hyphens (-) or double hyphens (--) to hide that they used AI. Which, of course, is its own tell.
But this still doesn't hide the most obvious giveaway, which isn't the em-dash itself. LLMs almost always put spaces around em-dashes: word — word instead of word—word. My guess is that models are heavily trained on news data, where the AP style guide, most commonly used in journalism, recommends spaces around em-dashes. Books and most professional writing use them without spaces.
So if you're taking your writing seriously, there's no way around learning how to use hyphens, en-dashes, and em-dashes correctly. I wrote a short post explaining the differences on my blog: Hyphens and Dashes
Context Windows Are Limited by Atoms, Not Bits
There is a popular narrative in tech right now: AI progress is exponential, context windows will grow to infinity, and all vertical AI products will soon be replaced by general-purpose AI that can use all the context of your entire business. This implies that the big players like Anthropic, OpenAI, and Google, with their general-purpose agents like Claude Cowork, ChatGPT, or Gemini, will subsume all software.
[... 828 words]10 Years Building Vertical Software: My Perspective on the Selloff. Nicolas Bustamante, who has built vertical software on both sides of the LLM disruption (Doctrine for legal, Fintool for equity research), wrote a moat-by-moat analysis of vertical SaaS that is worth reading. In his view, five moats collapse (learned interfaces, custom workflows, public data access, talent scarcity, and bundling), while five hold (proprietary data, regulatory lock-in, network effects, transaction embedding, and system-of-record status).
A few things I think are missing. The biggest threat to vertical software incumbents probably isn't scrappy AI startups building 80% of the features at 20% of the cost (like his new Fintool company). It's that products like Claude Cowork can do 80% of what vertical software does out of the box, with general agents and data access, at marginal implementation cost. Once integrated, enterprises might trust Anthropic, OpenAI, and Google more than they trust a vibe-coded startup.
There's also a scenario Bustamante doesn't address: LLMs themselves will likely commoditize. If that happens, model providers will have to fight for companies and startups to use their tokens. That's precisely why Anthropic, OpenAI, and Google are strongly pushing into the product space themselves, because products might be more defensible than models. This raises an uncomfortable question for Bustamante's own company, Fintool, which he doesn't address. If what they built is, as he describes, essentially markdown skill files integrating with MCPs and foundation model APIs, what's their justification against the model providers doing the same thing?
Is this where LLMs picked up their famous sycophantic phrase and behavior?
Currently reading Conscious Business by Fred Kofman, a classic on values and authentic communication at work, and stumbled across this on page 57.

On Conscious Business by Fred Kofman
Boris Cherny (creator of Claude Code) on Lenny’s Podcast. I hadn't come across the term "latent demand" before this podcast, and Boris Cherny calls it the single most important principle in product. The idea of latent demand is to watch how users misuse or hack your product to solve their own use cases, and then build specifically for that. Cherny also extends this to AI. With AI products, you should observe what the model/agent is trying to do (e.g., which data it wants to access, which tools are missing, or it has to chain together that could be implemented in a use-case specific tool call), and make that easier.
Cherny also had an interesting comment on innovation. You can't force it, but you have to give people space and psychological safety to fail, but cut ideas that aren't working. Claude Code itself wasn't explicitly on the roadmap, and it wasn't an obvious hit at launch.
He also shared an interesting observation on how roles in and around product are changing with AI. Everyone on the Claude Code team—engineers, PMs, designers, etc.—codes, but with a different angle. He thinks the term "software engineer" might disappear by the end of the year and be replaced by something broader, like "builder".
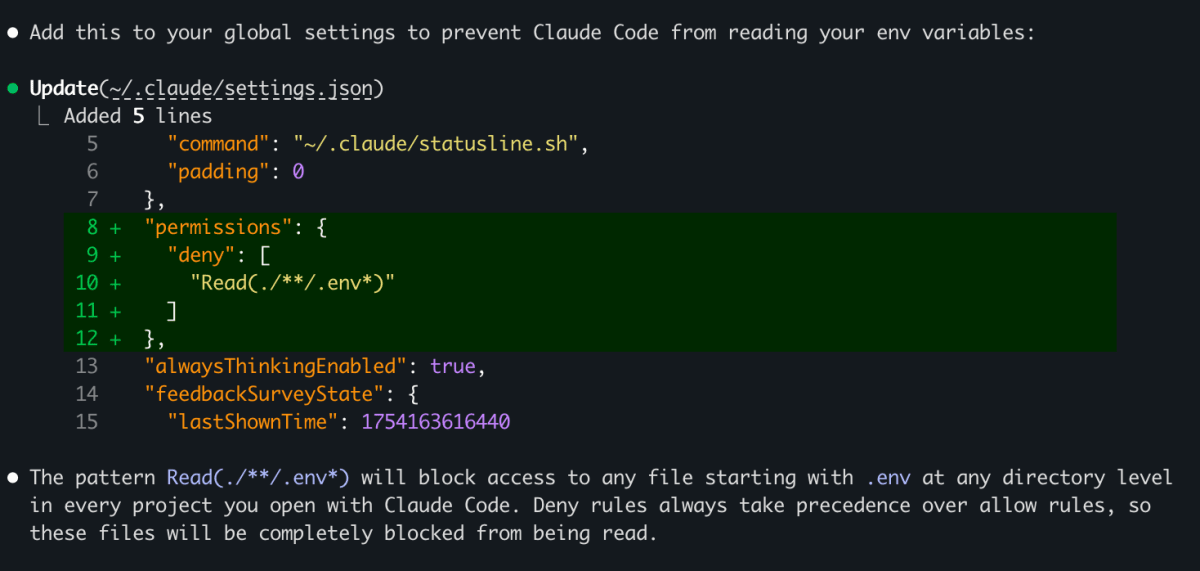
If you're using Claude Code or other coding agents, check whether they have access to your secrets. Many developers assume .env files are protected by default, but they are not.
In Claude Code, the interactive permission prompt is the only barrier, and it's easy to click through without thinking. To fix this, you can add a deny rule in your global Claude Code settings (see screenshot).
It takes 30 seconds to set up, and it's the kind of thing you only think about after something goes wrong.
An Interview with Ben Thompson by John Collison on the Cheeky Pint Podcast. John Collison and Ben Thompson sketch out four levels of agentic commerce in this interview. I like that they start from the bottom up instead of jumping to the far end state.
- Reduce friction. Agents that fill out web forms on your behalf. You paste a product URL into ChatGPT and say "buy this for me."
- Contextual search. Natural language queries with real context: "I need a jacket for -10°C in the Alps" instead of guessing keywords.
- Persistent preference profile. A profile the agent builds over time from your pins, browsing history, or style boards.
- Proactive recommendations. Don't wait for the user to search: anticipate what they need and surface it at the right time. Thompson's point is that this already exists at scale. Zuckerberg called Meta's ad platform the most successful agent in the world.
Interesting to think about how these four levels apply to Ren and other AI products. At Ren, we started from the hardest end, level 4, with proactive recommendations.
One could arguably add a level 5: full autonomy. The agent doesn't just recommend, it acts. OpenClaw is the most visible example right now: a local AI agent that browses, buys, books, and executes on your behalf without waiting for approval at each step.
For the first time, you can build a competitive recommender system without a single user.
The playbook behind the flywheel of many of the most powerful companies has been: build a platform, measure engagement data, identify patterns, and make better recommendations to attract more users. That's the network effect that made Google, Meta, and Amazon so hard to compete with.
But LLMs have a compressed representation of that same knowledge from training on vast amounts of the internet. So to overcome the cold-start problem, you no longer need to measure and train on years of engagement data from your own users.
Now you can just give an LLM some context of a user, for example, their social media profile, to get high-quality recommendations. It's a fundamentally different entry point to personalization, one that doesn't depend on scale.
Are LLMs about to break the recommender-system moat?
An Interview with Benedict Evans About AI and Software. Benedict Evans articulates a great insight really well here: LLMs might be a real threat to recommender system moats.
The playbook to build a flywheel has been the following: build a platform, measure engagement data, find patterns, and make better recommendations to attract more users. That's the network effect that made Google, Meta, and Amazon so hard to compete with. But LLMs have a compressed representation of that same knowledge from training on vast amounts of the internet, without having to measure engagement of real users.
To overcome the cold-start problem, you don't need years of engagement data anymore. Now you can just give an LLM some context of a user, for example their social media profile, to get high-quality recommendations. It's a fundamentally different entry point to personalization, one that doesn't depend on scale.
OpenClaw took the internet by storm last week. It's obviously a security nightmare, but its viral success confirms something I've believed for a while: most AI products today are fundamentally limited by requiring too much agency from their users.
There's real demand for AI that works for you, not just with you. A system that monitors, anticipates, and acts proactively instead of waiting for your next prompt.
At Ren Systems, we've been building exactly this kind of product: AI that works on behalf of the user and surfaces what matters before they ask for it. There's something almost magical when an AI system works this way.
Proactive AI is where the next value unlock lies. But building it in a way that's secure and compliant isn't something you can prompt out of Claude Code overnight.